Deploying a YOLOv8 model in the cloud presents challenges in balancing speed, cost, and scalability. Utilizing a GPU server offers fast processing but comes at a high cost, especially for sporadic usage. Conversely, opting for a CPU-only server is more economical but sacrifices speed and scalability, requiring complex setups to scale with incoming requests. An effective solution lies in leveraging serverless architectures such as AWS Lambda. Despite its CPU-only setup, AWS Lambda offers seamless scalability, supporting up to 1000 workers in parallel without any complexity. Moreover, you pay solely for the actual compute time, eliminating charges for idle periods.
In this blog post, I will guide you through deploying a YOLOv8 model on AWS Lambda, with little effort. We will be using the newly introduced “Function URLs” option, which allows us to directly trigger the Lambda function over HTTP, without using AWS Gateway. You can find the accompanying code here.
Converting YOLOv8 to ONNX
A crucial consideration when working with serverless functions is the need to keep the deployment package as compact as possible. This is important for two key reasons. First, deployment sizes are typically capped at a fixed size (250MB with AWS Lambda when deploying from a Zip package). Second, a smaller package translates to reduced cold-start times for the function. To achieve this, rather than relying on the default Ultralytics package, we’ll export the model to ONNX and use our own ONNX inference library, YOLO-ONNX, which can be found here. This library is ideal for cloud deployments and embedded devices as it requires only minimal dependencies.
So, the first step is to convert your YOLOv8 model to ONNX. As an example, we will convert the COCO-pretrained YOLOv8n model. You can follow the same steps to convert your custom model. Want to know how you can train your own custom YOLOv8 detection model, look at my post here.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This will result in a new file, “yolov8n.onnx”, which we will deploy using our Lambda function. Note that it is important to set the flag “dynamic”, as this will allow us to run the model with different input sizes, depending on the aspect ratio of the image.
The Lambda function
There are various methods available for deploying a Lambda function on AWS. In this scenario, I will opt for AWS SAM (Serverless Application Model), which streamlines the process of creating and updating Lambda functions with minimal complexity. Please be aware that you’ll need to install the SAM library, and you can find installation instructions here. To follow along, you can download the codebase from this link.
If using SAM, you need to place your codebase within a designated folder and include a requirements file listing the necessary libraries. Our folder structure looks as follows:
Within the model’s directory, you should put the ONNX model that we converted before. For increased versatility, an alternative approach could involve uploading the model to an S3 bucket and downloading it at runtime. However, we leave that for another post.
In the “requirements.txt” file, you’ll list the dependencies necessary for your setup. In this specific case, the sole requirement will be our ONNX inference library.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
The YOLOv8 model is initialized as a global variable. This way, the model remains in memory during the lifetime of the function and doesn’t have to be re-initialized with every function call.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
The incoming request is parsed and the relevant info is extracted. For this example, I will pass the input image as a b64-encoded string, but another option might be to pass the URL to the image and download the image locally. Optionally, I also provide the option to pass the image size, confidence threshold, and IOU threshold.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
The image is decoded, after which it is passed to the model and the detected objects are returned.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Before deploying the lambda function with SAM, you first need to define the template in “template.yaml”:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
It’s quite straightforward, so I won’t go into much detail. The only thing worth mentioning is that I set the memory size of the function to the maximum value of 10240MB. By doing so, the maximum amount of cores (6) is assigned to the function, increasing its performance. I also set the authentication to NONE, so the API is easily accessible for this demo. However, for a production setting, it is a good idea to add some authentication.
Now you can build the function using the command line:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Note that with the flag “use-container”, the function is built within a docker container. When succeeded, the function URL will be printed in the terminal.
Test the Lambda function
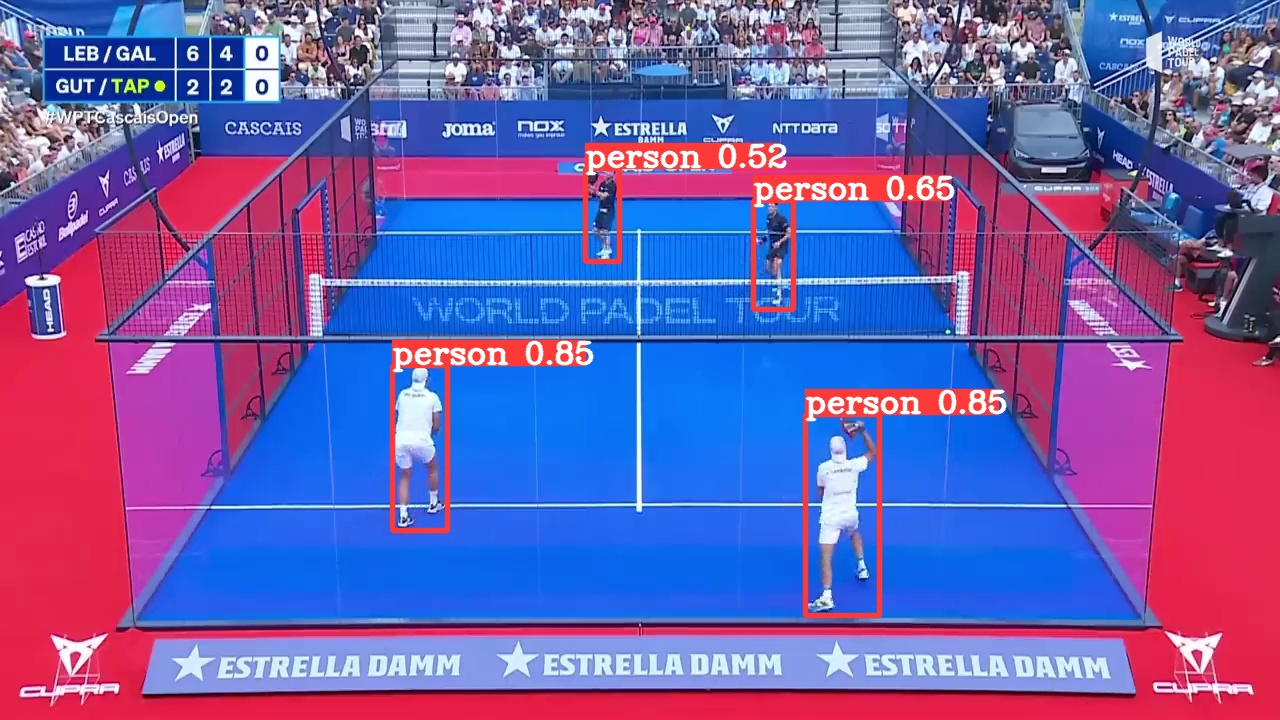
Let’s test our deployed lambda function. For this, I wrote a small Python script, but you can trigger the API using your preferred language. The script encodes an image to a b64-encoded string and queries our endpoint. Next, the returned predictions are displayed on the image using OpenCV.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
In this blog post, I’ve demonstrated the deployment of a YOLOv8 detection model on AWS Lambda. When appropriately configured, this setup becomes a powerful inference server, making it well-suited for integration into a production environment where it can efficiently scale to handle a high volume of requests.
By clicking “Accept All Cookies”, you agree to the storing of cookies on your device to enhance site navigation, analyze site usage, and assist in our marketing efforts. View our Privacy Policy for more information.